* 이 포스트는 Coursera에 있는 Andrew Ng 교수님의 강의 Machine Learning(링크)를 바탕으로 작성되었습니다.
Model Representation
Machine Learning에서 값을 예측할 때 기존에 가지고 있는 데이터를 이용해 Training 시키는데, 저번 포스팅에 들었던 예시 중에 집의 크기를 통한 가격 예측을 생각해보자.
여기서 기존에 가지고 있는 데이터는 다른 집들의 평수(xi)와 가격(yi)일 것이고 예측하려고 하는 것은 어떤 평수(x)를 가진 집의 가격(y)일 것이다.
앞으로 이렇게 어떤 특성을 이용해 그와 연관되는 값을 알려고 할 때 편의상 그 특성을 x라 하고 예측하려고 하는 속성을 y라고 하자.
또한 기존에 m개의 데이터가 있다고 한다면 i번째 데이터의 특성 값을 xi라 하고 그에 대응되는 결과 값을 yi이라고 하자.
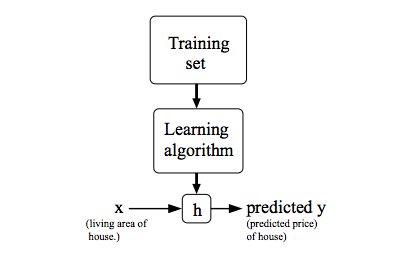
한편, Machine Learning에서는 예측하려는 값에 대한 함수를 설정한다. 보통 데이터의 분포를 보고 함수의 개형을 다항함수, 지수함수 등의 형태로 잡는데 이러한 함수를 hypothesis function이라 하고 h(x)라고 쓴다.
만약,
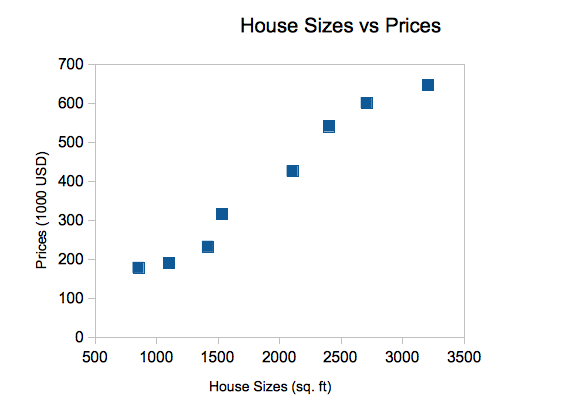
실제로 이런 데이터의 분포를 가진다면 h(x)를 일차식의 형태로 세울 수 있을 테고 이를 식으로 나타내면 다음과 같다.(앞으로는 θ의 값을 어떻게 설정해야 하는지 볼 예정)
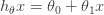
Cost Function
원하는 값을 예측하기 위해 세운 hypothesis function의 정확도를 측정하기 위해서 Cost Function을 사용한다.
Linear Regression의 Cost Function에서는 간단히 말하자면 가지고 있는 데이터의 x값(xi)을 hypothesis function에 넣은 예측값 h(xi)의 값과 실제 데이터의 y값(yi)의 차를 이용한다.
한편, 설정한 함수가 예측한 값이 실제 데이터와 차이가 별로 없어야 좋은 예측이라고 할 수 있는데 그 차가 양수 혹은 음수이므로 그 차들을 바로 더하면 좋은 예측인지 판단할 수 없다.
따라서 m개의 데이터에 해당되는 차들의 제곱의 합(squared error)을 2m으로 나눈 값이 Cost Function의 식(J(θ))이다.(squared error의 mean에 2를 나눈 값; 2는 미분했을 때 나오는 상수를 제거하기 위해서 나눔)
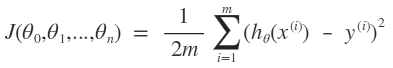
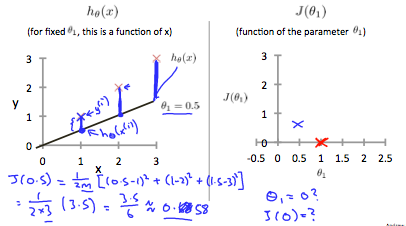
Linear Regression
hypothesis function 중에서 가장 간단한 모델은 위에서 예로 들었던 일차함수이다.
Cost Function을 최소로 하는 일차식으로 형성된 hypothesis function으로 원하는 값을 예측하는 것을 linear regression이라고 한다.
Linear Regression에서 cost function은
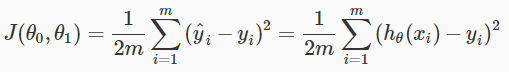
이고, θ0이 x축, θ1이 y축 이면서 J(θ)를 표현하는 그래프는 다음의 오른쪽과 같다.
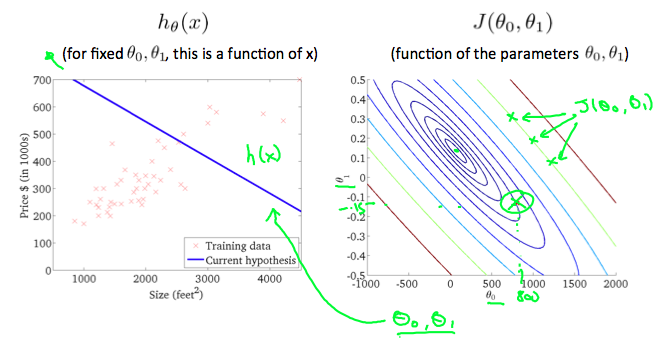
J(θ)가 작을수록 설정한 hypothesis function을 잘 만들었다고 할 수 있는데 위의 그래프에서는 θ0이 대략 100, θ1이 대략 0.15일때 최소가 된다고 할 수 있다.
다음 포스팅에는 이 최소값을 구하는 방법인 Gradient Descent에 대해서 알아보겠다.