이 포스트는 구글 머신러닝 스터디 1주차 공부 내용 중 tensorflow에 관한 부분을 정리해보았다.
텐서플로우 첫 걸음
1. 라이브러리 로드

[1] from __future__ -> 이전 버전의 파이썬에서도 새롭게 나타난 함수를 사용하게 만들어 줌
[2] matplotlib cm -> colormap
gridspec -> customize figure layout of plots
[3] tf.logging.set_verbosity(tf.logging.ERROR) -> Sets the threshold for what messages will be logged.
2. 데이터 세트 로드
3. 데이터 조사
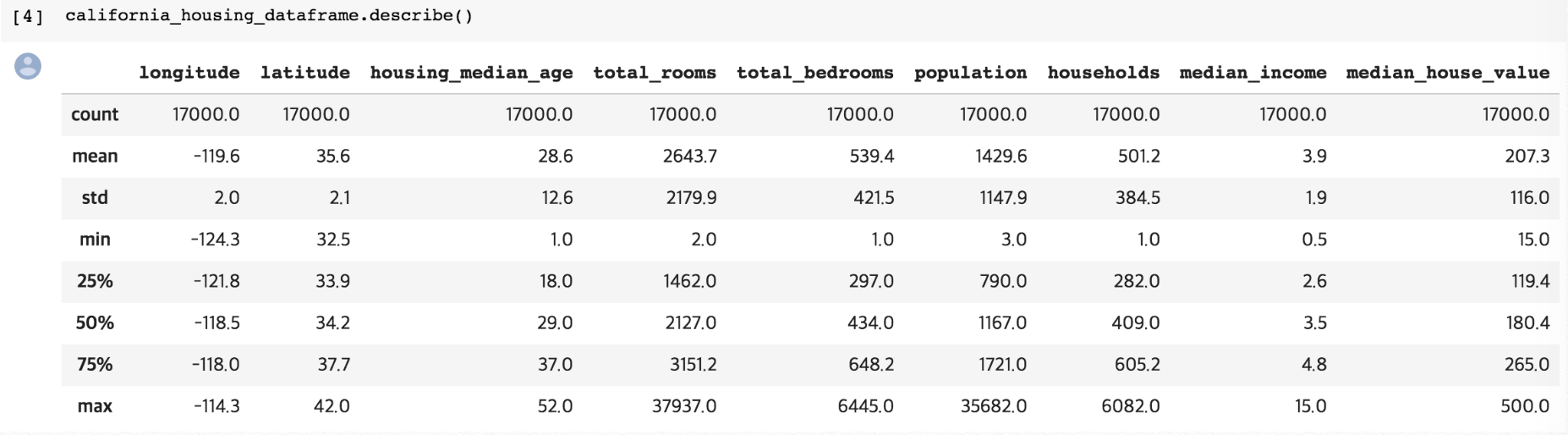
[1] 데이터를 본격적으로 다루기 전에 한 번 살펴보는 것이 좋음 (with pandas.describe)
4. 첫 번째 모델 만들기
- total_rooms(입력 특성)를 통한 median_house_value(라벨) 예측 모델
- tf.estimator API의 LinearRegressor Interface 사용 (저수준, 사용하기 편리하지만 세부사항 건들 순 없음)
4-1. 특성 정의 및 특성 열 구성
data를 TF로 가져오려면 각 특성에 들어있는 데이터 유형을 지정해야 함. 주로 2가지 데이터 유형을 사용함.
- 범주형 데이터: 텍스트로 이루어진 데이터. 지금의 주택 데이터 세트는 범주형 데이터를 포함하지 않음.
- 수치 데이터: 정수 또는 부동 소수점 숫자이며 숫자로 취급하려는 데이터. 우편번호 등의 수치 데이터는 범주형으로 취급하는 경우도 있음.

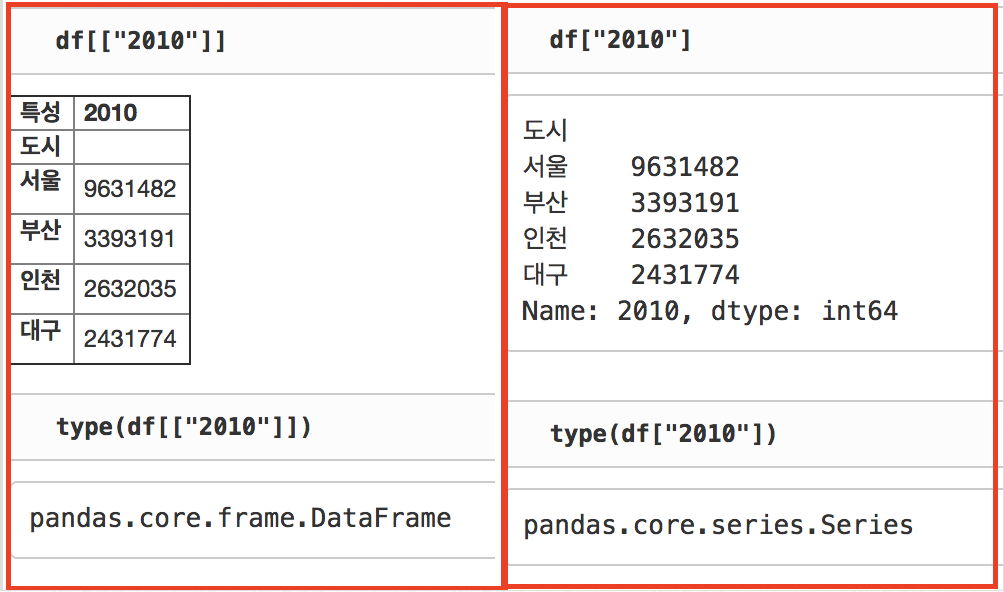
[1] [“total_rooms”] 대신에 [[“total_rooms”]]를 사용하는 이유 [참조 링크]
-> pandas의 Dataframe을 인덱싱 할 때 라벨 값을 인덱스로 넣으면 Series객체가 변환되고, 라벨의 배열 또는 리스트를 넣으면 부분적인 Dataframe이 변환됨
[2] tf.feature_column.numeric_column을 통해 2가지 데이터 유형 중 수치 데이터로 특성 열 정의
4-2. 타겟 정의
타겟인 median_house_value를 정의함
4-3. LinearRegressor 구성

[1] SGD를 구현하는 GradientDescentOptimizer를 통한 Linear Regression 모델 구성
[2] clip_gradients_by_norm -> 학습 중 gradient가 너무 커져서 실패하는 경우를 방지하는 경사 제한
[3] LinearRegressor에 특성 열과 optimizer (모델을 train시키는 API 정의 시킴)를 넣어서 구성함
4-4. 입력 함수 정의
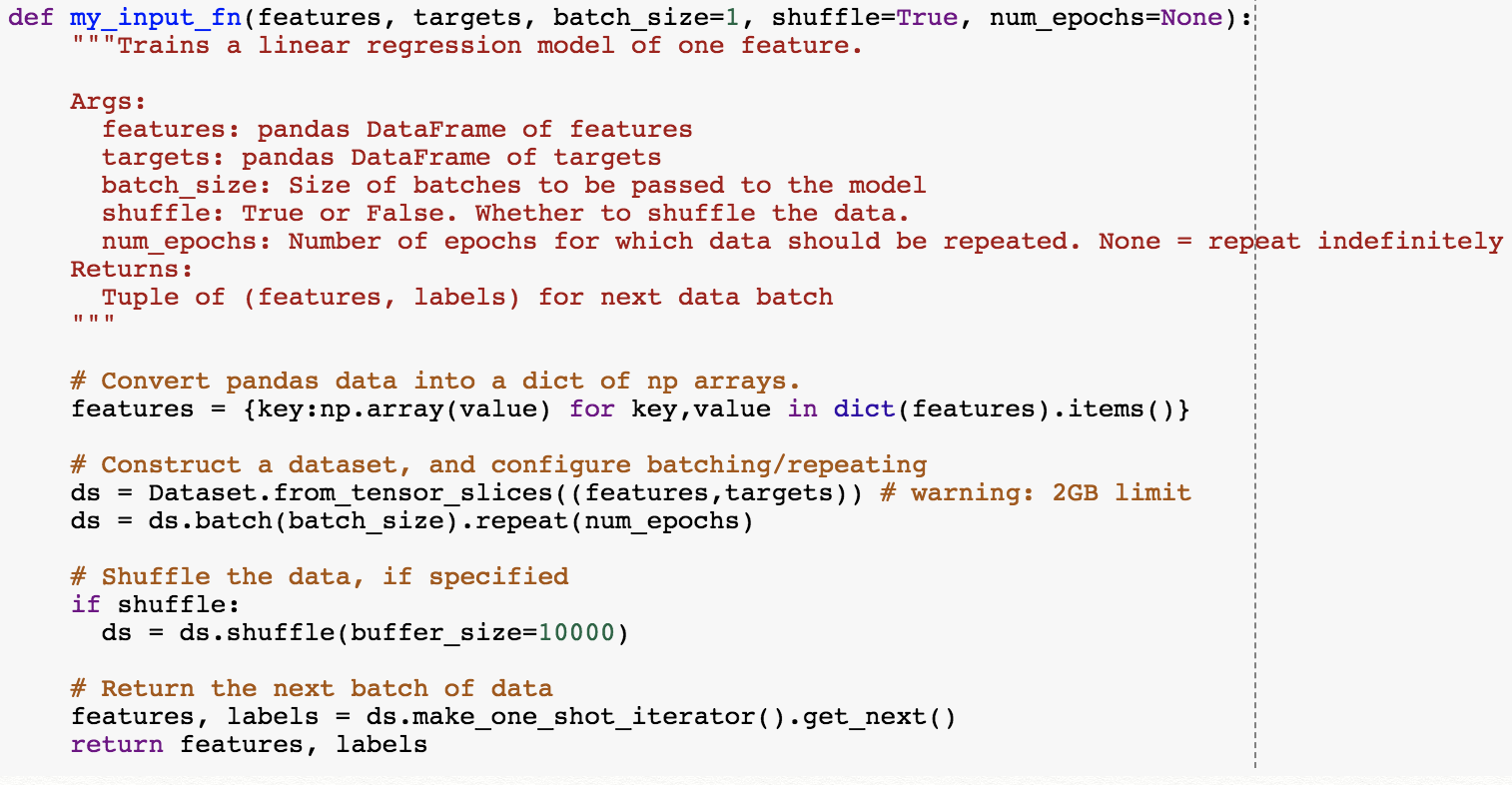
[1] 데이터를 Linear Regressor로 전달하기 위해서는 데이터 전처리 방법 및 모델 학습 중의 일괄 처리, 셔플, 반복 방법을 알려주는 입력 함수를 정의해야 함.
[2] feature(DataFrame)를 np.array를 가진 dict로 변환
-> np.array로 변환해서 저장하는 이유: 하나의 key를 가진 dict 생성
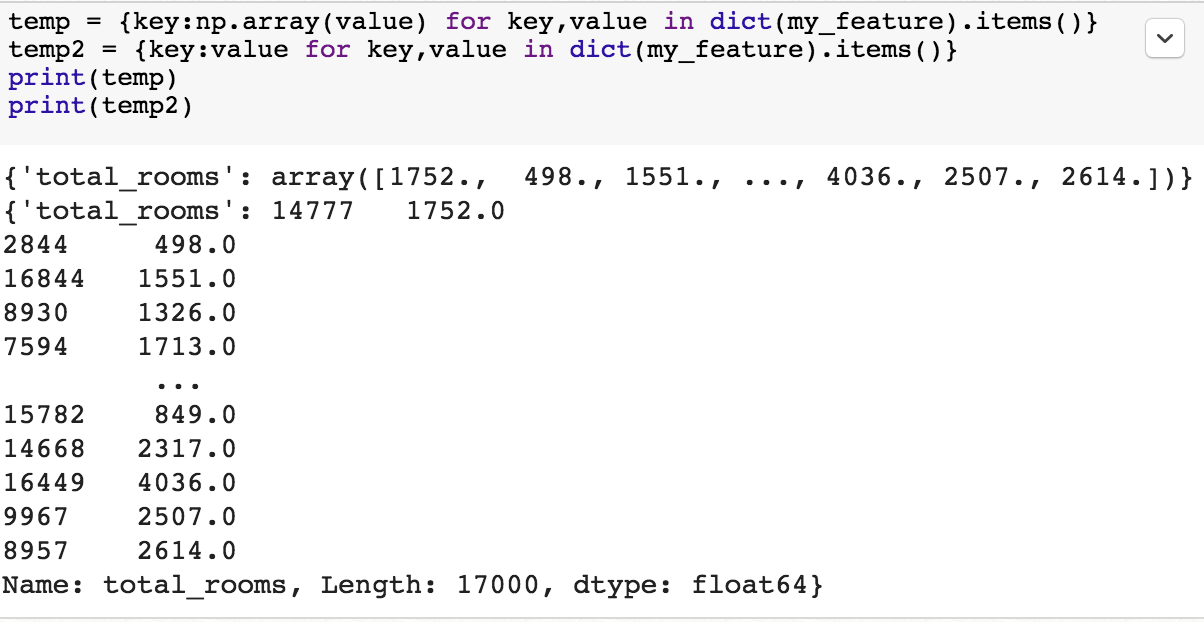
[3] from_tensor_slice-> numpy array를 dataset으로 바꿔 줌 [Dataset 관련 링크]
[4] iterator를 통해서 데이터 집합을 반복하고 실제 값을 받을 수 있음. 4가지 타입이 있음 [참조 링크]

[5] Tensorflow’s guide to Import Data [참조 링크]
4-5. 모델 학습

[1] 이제 linear_regressor의 train을 이용해서 학습을 시킬 수 있음. [텐서플로우 입력 함수 가이드]
4-6. 모델 평가

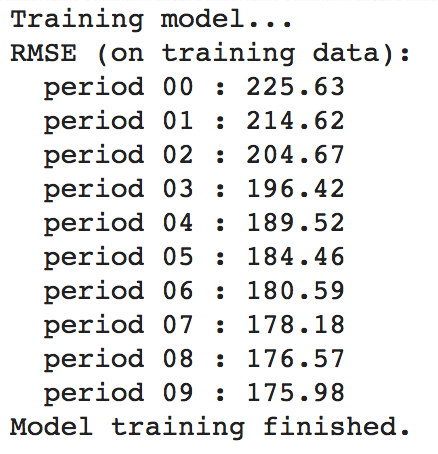
[1] RMSE(평균 제곱근 오차)로 해석: 원래 target과 동일한 척도로 해석 가능
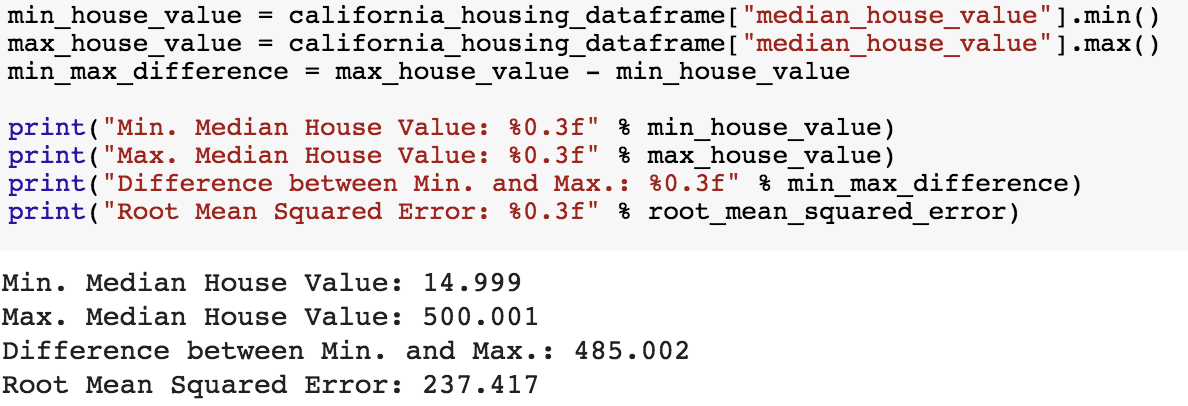
[1] 오차 범위를 비교 했더니 target 값 범위의 절반. 줄일 필요가 있음
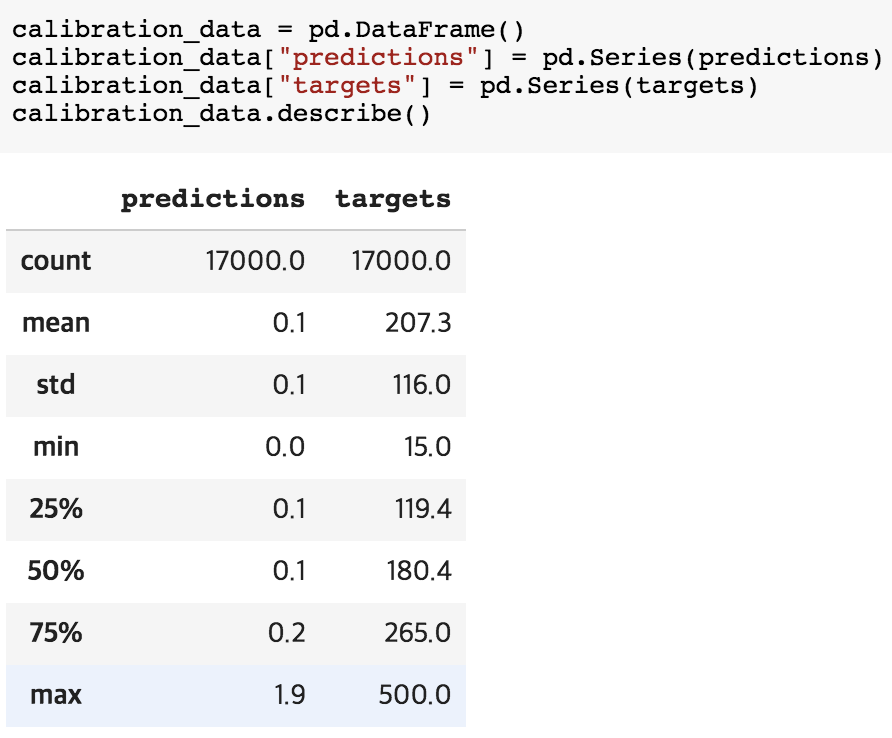
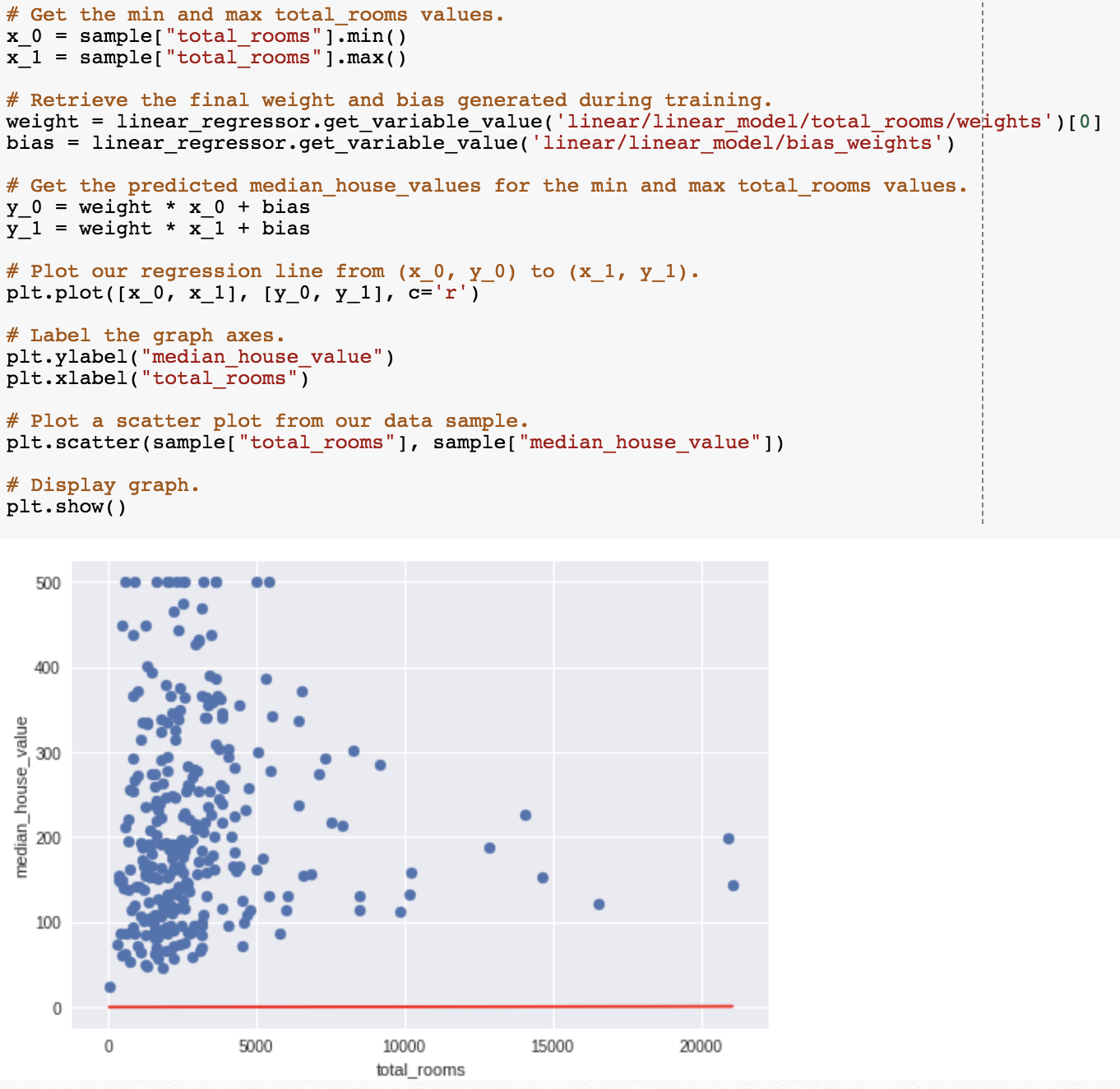
[1] 자세히 살펴보니 많이 벗어나 있음
4-7. 모델 초매개변수 수정

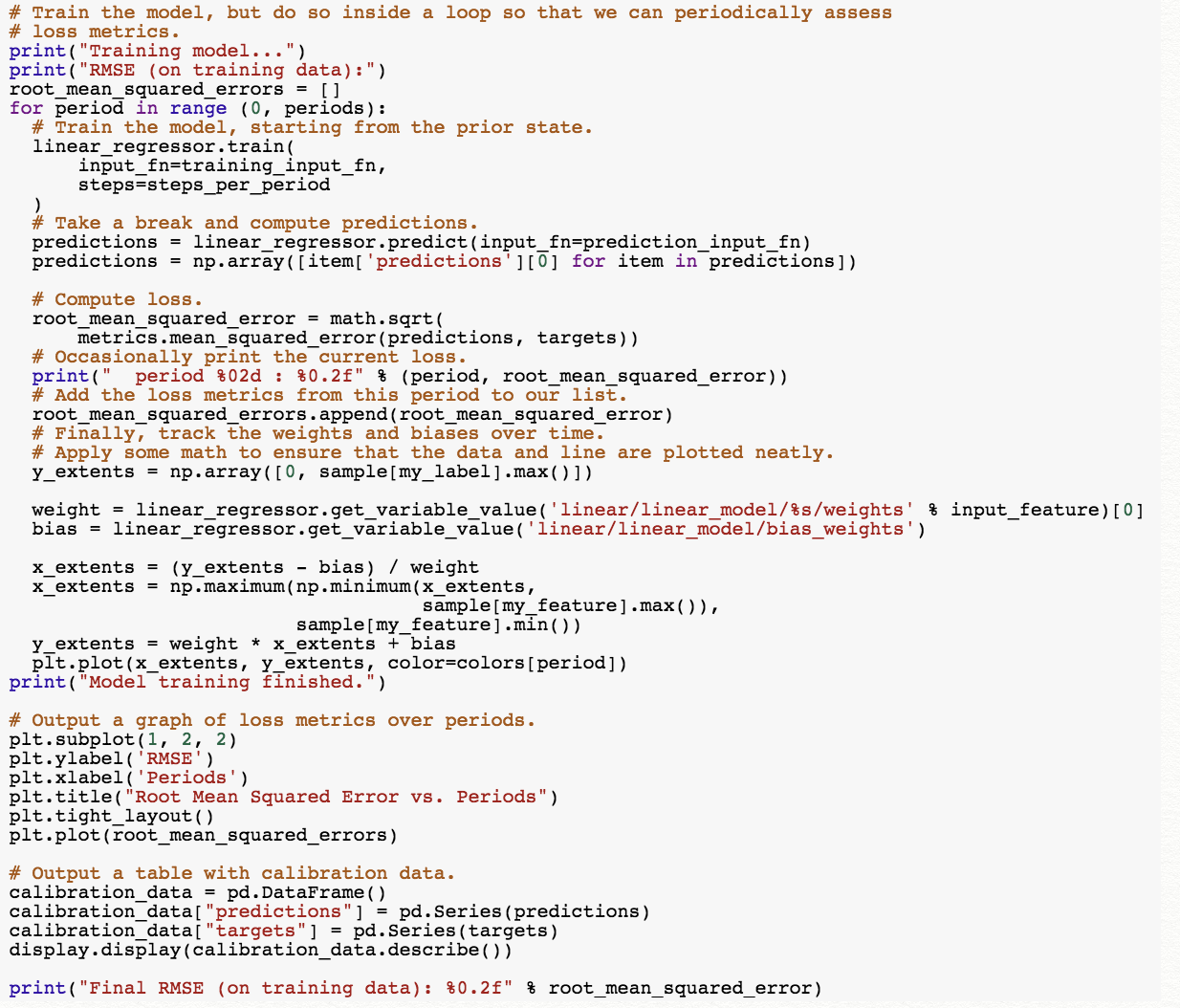
[1] 위 코드는 지금까지 했던 코드를 종합한 건데, 차이점은 learning rate, step size, batch size를 설정할 수 있다는 것임.
(전에 넣었던 learning rate는 0.0000001, batch size = 1, step size = 100)
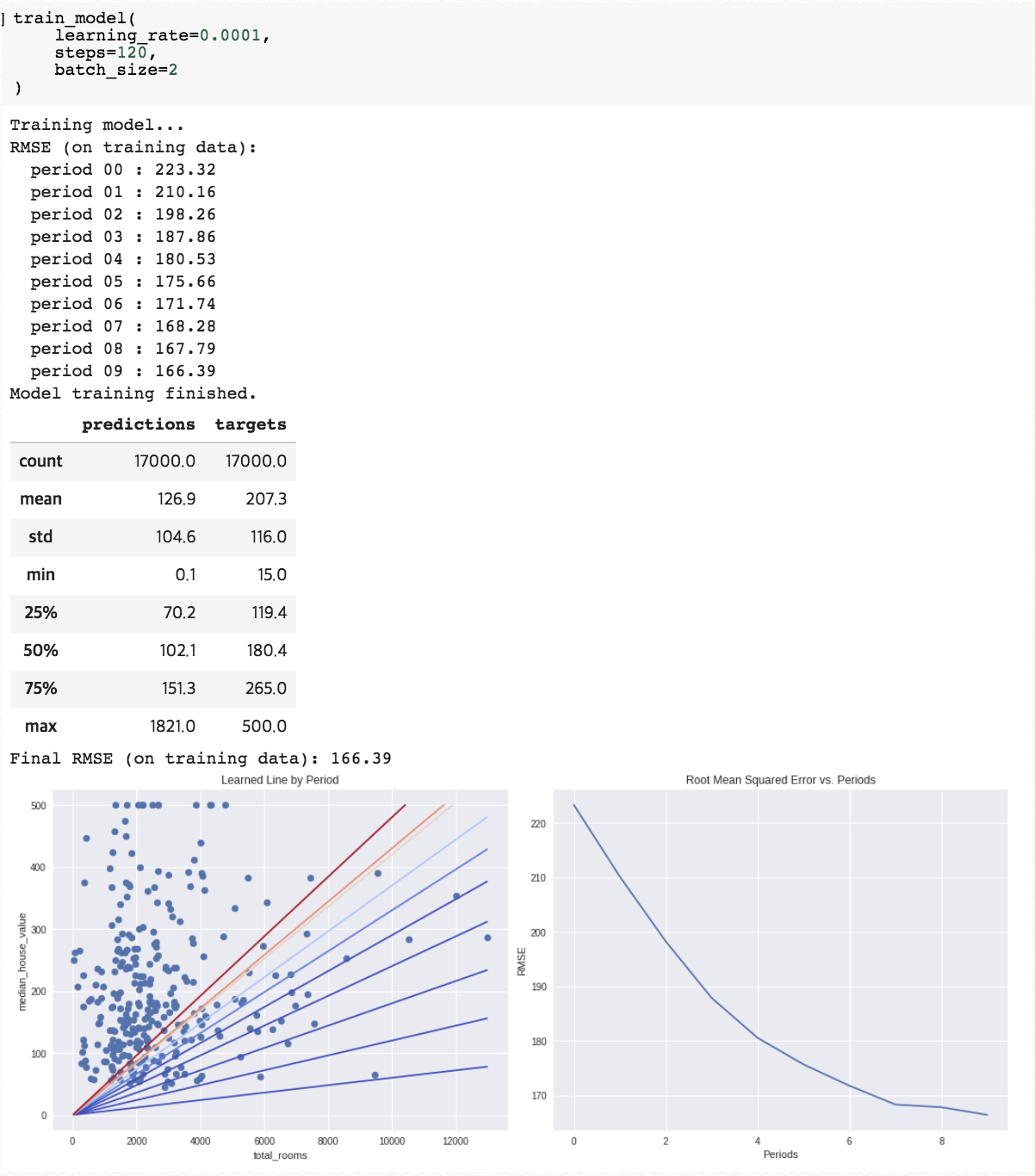
[2] 초 매개변수를 위와 같이 수정하니 RMSE가 180 아래(166.39)로 떨어짐

[1] input feature도 population으로 변경 가능함.
결과->