Coursera 강의 “Machine Learning with TensorFlow on Google Cloud Platform” 중 세 번째 코스인 Intro to TensorFlow의 2주차 강의노트입니다.
Estimator API
Estimatorswrap up a large amount of boilerplate code, on top of the model itself.
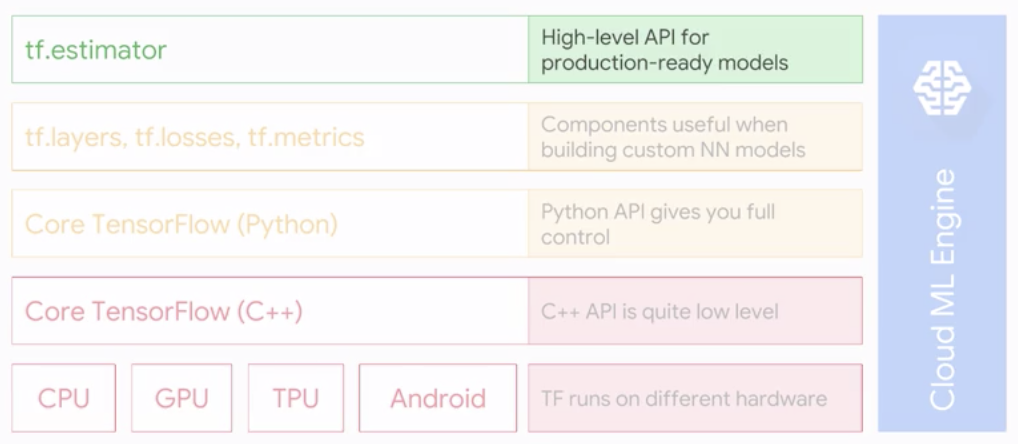
- From small to big to prod with the
Estimator API- Quick model
- Checkpointing
- Out-of-memory datasets
- Train / eval / monitor
- Distributed training
- Hyper-parameter tuning on ML-Engine
- Production: serving predictions from a trained model
Pre-made estimatorsthat can all be used in the same way.

tf.estimator.Estimator
Pre-made Estimators
- Feature columns tell the model
what inputs to expect
import tensorflow as tf
featcols = [ tf.feature_column.numeric_column("sq_footage"), tf.feature_column.categorical_column_with_vocabulary_list("type", ["house", "apt"]) ]
model = tf.estimator.LinearRegressor(featcols)- Under the hood: feature columns take care of packing the inputs into the input vector of the model
- tf.feature_column.
bucketized_column - tf.feature_column.
embedding_column - tf.feature_column.
crossed_column - tf.feature_column.
categorical_column_with_hash_bucket - …
- tf.feature_column.
Training: feed in training input data and train for 100 epochs
def train_input_fn():
features = {"sq_footage": [1000, 2000, 3000, 1000, 2000, 3000],
"type": ["house", "house", "house", "apt", "apt", "apt"]}
labels = [500, 1000, 1500, 700, 1300, 1900]
return features, labels
model.train(train_input_fn, steps=100)Predictions: once trained, the model can be used for prediction
def predict_input_fn():
features = {"sq_footage": [1500, 1800],
"type": ["house", "apt"]}
return features
predictions = model.predict(predict_input_fn)- To use a different pre-made estimator, just change the class name and supply appropriate parameters
model = tf.estimator.DNNRegressor(featcols, hidden_units=[3, 2])Checkpointing
- Model checkpoints
- Continue training
- Resume on failure
- Predict from trained model
- Estimators
automaticallycheckpoint training
model = tf.estimator.LinearRegressor(featcols, './model_trained') # Where to put the checkpoints
model.train(train_input_fn, steps=100)%ls model_trained
checkpoint model.ckpt-100.meta
graph.pbtxt model.ckpt-1.data-00000-of-00001
model.ckpt-100.data-00000-of-00001 model.ckpt-1.index
model.ckpt-100.index model.ckpt-1.meta- We can now restore and predict with the model
trained_model = tf.estimator.LinearRegressor(featcols, './model_trained')
predictions = trained_model.predict(pred_input_fn)INFO:tensorflow:Restoring parameters from
model_trained/model.ckpt-100
{'predictions': array([855.93], dtype=float32)}
{'predictions': array([859.07], dtype=float32)}- Training also resumes from the last checkpoint
Training on in-memory datasets
- In memory data: usually numpy arrays or Pandas dataframes
tf.estimator.inputs.numpy_input_fntf.estimator.inputs.pandas_input_fn
- Training happens until input is exhausted or number of steps is reached
def pandas_train_input_fn(df): # a Pandas dataframe
return tf.estimator.inputs.pandas_input_fn(
x = df,
y = df['price'],
batch_size=128,
num_epochs=10,
shuffle=True
)
# Trains until input exhausted (10 epochs) starting from checkpoint
model.train(pandas_train_input_fn(df))
# 1000 additional steps from checkpoint
model.train(pandas_train_fn(df), steps=1000)
# 1000 steps - might be nothing if checkpoint already there
model.train(pandas_train_input_fn(df), max_steps=1000)- To add a new feature, add it to the list of feature columns and make sure it is present in data frame
Train on large datasets with Dataset API
- Real World ML Models
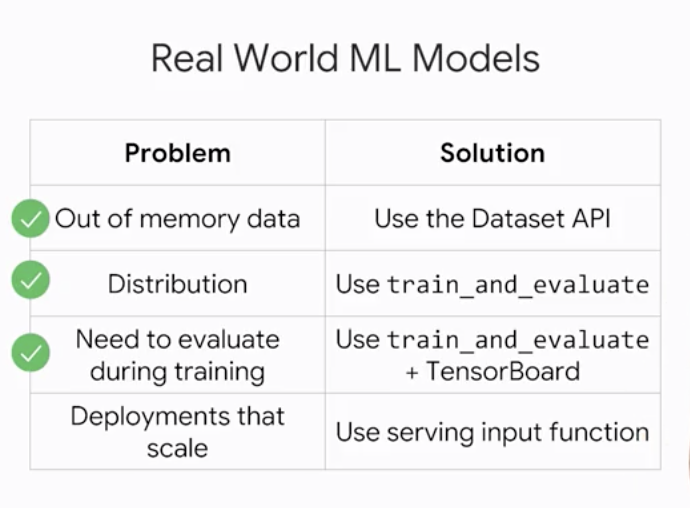
Reak World ML Models
- Out-of memory datasets tend to be
sharded into multiple files - Datasets can be created from different file formats. They generate
input functionsfor Estimators - Read one CSV file using
TextLineDataset - Datasets handle shuffling, epochs, batching, …
- They support arbitrary transformations with
map() - Datasets help create
input_fn’s for Estimators
def decode_line(row):
cols = tf.decode_csv(row, recode_defaults=[[0],['house'],[0]])
features = {'sq_footage': cols[0], 'type': cols[1]}
label = cols[2] # price
return features, label
dataset = tf.data.TextLineDataset("train_1.csv").map(decode_line)
dataset = dataset.shuffle(1000).repeat(15).batch(128)
def input_fn():
features, label = dataset.make_one_shot_iterator().get_next()
return features, label
model.train(input_fn)- All the tf.commands that you write in Python do not actually process any data, they just build graphs.
- Common Misconceptions about
input_fn- Input functions called
only once - Input functions return
tf nodes(not data)
- Input functions called
- The real benefit of Dataset is that you can do more than just ingest data
dataset = tf.data.TextLineDataset(filename)\
.skip(num_header_lines)\
.map(add_key)\
.map(lambda feats, labels: preproc(feats), labels)
.filter(is_valid)\
.cache()Big jobs, Distributed training
estimator.train_and_evaluateis the preferred method for training real-world models.- data parallelism = replicate your model on multiple workers
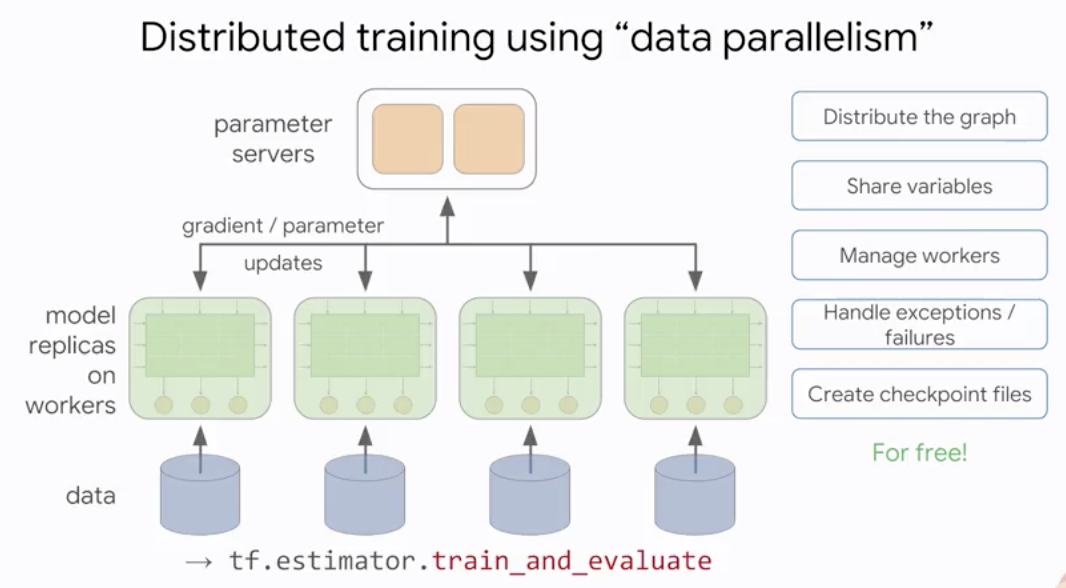
Distributed training using dataparallelism
estimator.train_and_evaluateis the preferred method for training real-world models
estimator = tf.estimator.LineRegressor(
feature_colimns=featcols,
config=run_config)
...
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)RunConfigtells the estimator where and how often to write Checkpoints and Tensorboard logs (“summaries”)
run_config = tf.estimator.RunConfig(
model_dir=output_dir,
save_summary_steps=100,
save_checkpoints_steps=2000)
estimator = tf.estimator.LineRegressor(config=run_config, ...)- The
TrainSpectells the estimator how to get training data
train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn, max_steps=50000)
...
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)- The
EvalSpeccontrols the evaluation and the checkpointing of the model since they happen at the same time
eval_spec = tf.estimator.EvalSpec(
input_fn=eval_input_fn,
steps=100, # evals on 100 batches
throttle_secs=600, # eval no more than every 10 min
exporters=...)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)Shufflingis even more important in distributed training
dataset = tf.data.Dataset.list_files("train.csv-*") \
.shuffle(100) \
.flat_map(tf.data.TextLineDataset)\
.map(decode_csv)
dataset = dataset.shuffle(1000) \
.repeat(15) \
.batch(128)Monitoring with TensorBoard
- Point Tensorboard to your output directory and the dashboards appear in your browser at localhost:6006
Pre-madeEstimators export relevant metrics, embedding, histograms, etc. for TensorBoard, so there is nothing more to do
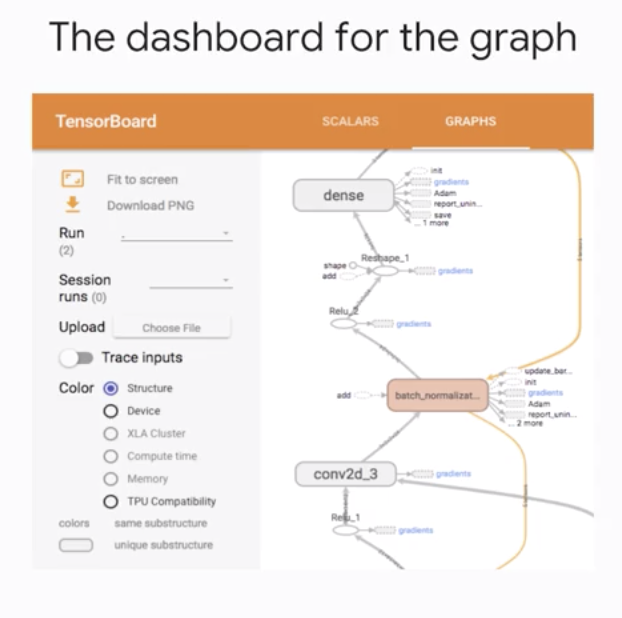
The dashboard for the graph
- If you are writing a custom Estimator model, you can add
summariesfor Tensorboard with a single line.- Sprinkle appropriate summary ops throughout your code:
tf.summary.scalartf.summary.imagetf.summary.audiotf.summary.texttf.summary.histogram
tf.summary.scalar('meanVarl', tf.reduce_mean(varl))
...
tf.summary.text('outClass', stringvar)Serving Input Function
- Recap with all the code
run_config = tf.estimator.RunConfig(model_dir=output_dir, ...)
estimator = tf.estimator.LineRegressor(featcols, config=run_config)
train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn, max_steps=1000)
export_latest = tf.estimator.LatestExporter(serving_input_receiver_fn=serving_input_fn)
eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn, exporters=export_latest)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)Servingandtraining-time inputs are often verydifferent

- Serving input function transforms from
parsed JSON datato thedata your model expects

- The exported model is ready to
deploy - Example serving input function that decodes JPEGs
def serving_input_fn():
json = {'jpeg_bytes': tf.placeholder(tf.string, [None])}
def decode(jpeg):
pixels = tf.image.decode_jpeg(jpeg, channels=3)
return pixels
pics = tf.map_fn(decode, json['jpeg_bytes'], dtype=tf.unit8)
features = {'pics': pics}
return tf.estimator.export.ServingInputReceiver(features, json)