Coursera 강의 “Machine Learning with TensorFlow on Google Cloud Platform” 중 네 번째 코스인 Feature Engineering의 강의노트입니다.
Raw Data to Feature
- Feature Engineering
- Scale to large datasets
- Find good features
- Preprocess with Cloud MLE
- What raw data do we need to collect to predict the price of a house?
- Lot Size
- Number of Rooms
- Location
- …
- Raw data must be mapped into
numerical feature vectors
Good vs Bad Features
- What makes a good feature?
- Be
relatedto the objective - Be known at
prediction-time - Be
numericwithmeaningful magnitude - Have
enough examples - Bring
human insightto problem
- Be
- Different problems in the same domain may need
different features - Some data could be known
immediately, and some other data is not known in real time - You cannot train with current data and predict with
stale data - Avoid having values of which you don’t have
enough examples
Representing Features
-
Raw data are converted to numeric features in different ways
-
Numeric values can be used
as-is(real value) -
Overly specificattributes should bediscarded -
Categorical variables should be
one-hot encoded
tf.feature_column.categorical_coulmn_with_vocabulary_list(
'employeeId',
Vocabulary_list = ['8345', '72365', '87654', '23451'])
-
Preprocess data to create a
vocabularyof keys- The vocabulary and the mapping of the vocabulary needs to be
identical at prediction time
- The vocabulary and the mapping of the vocabulary needs to be
-
Options for encoding categorical data
- If you know the keys beforehand:
tf.feature_column.categorical_coulmn_with_vocabulary_list(
'employeeId',
Vocabulary_list = ['8345', '72365', '87654', '23451'])
-
If your data is already indexed; i.e., has integers in[0-N):
tf.feature_column.categorical_coulmn_with_identity( ‘employeeId’, num_bucket = 5)
-
If you don’t have a vocabulary of all possible values:
tf.feature_column.categorical_coulmn_with_hash_bucket( ‘employeeId’, hash_bucket_size = 500)
-
Don't mixmagic number with data
ML vs Statistics
ML= lots of data, keep outliers and build models for themStatistics= “I’ve got all the data I’ll ever get”, throw away outliers- Exact floats are not meaningful
- Discretize floating point values into
bins
- Discretize floating point values into
- Crazy outliers will hurt trainability
- Ideally, features should have a similar range (Typically [0, 1] or [-1, 1])
Preprocessing Feature Creation
- Feature engineering often requires global statistics and vocabularies
features['scaled_price'] = (features['price'] - min_price) / (max_price - min_price)
tf.feature_column.categorical_column_with_vocabulary_list('city',
keys=['San Diego', 'Los Angeles', 'San Francisco', 'Sacramento'])
-
Things that are commonly done in preprocessing (In TensorFlow)
- Scaling, discretization, etc. of numeric features
- Splitting, lower-casing, etc. of textual features
- Resizing of input images
- Normalizing volume level of input audio
-
There are two places for feature creation in TensorFlow
1. Features are preprocessed in input_FN (train, eval, serving)
features['capped_rooms'] = tf.clip_by_value(
features['rooms'],
clip_value_min=0,
clip_value_max=4
}
# 2. Feature columns are passed into the estimator during construction
lat = tf.feature_column.numeric_column('latitude')
dlat = tf.feature_column.bucketized_column(lat,
boundaries=np.arange(32,42,1).tolist())
Feature Cross
- Using non-linear inputs in a linear learner
- Dividing the input space with two lines yields four quadrants
- The weight of a cell is essentially the prediction for that cell
- Feature crosses
memorize - Goal of ML is
generalization - Memorization works when you have
lots of data - Feature crosses bring a lot of power to linear models
- Feature crosses +
massive datais an efficient way for learning highly complex spaces - Feature crosses allow a linear model to memorize large datasets
- Optimizing linear models is a convex problem
- Feature crosses,as a preprocessor, make neural networks converge a lot quicker
- Feature crosses +
- Feature crosses combine
discrete/categoricalfeatures - Feature Crosses lead to
sparsity
Implementing Feature Crosses
- Creating feature crosses using TensorFlow
day_hr = tf.feature_column.crossed_column([dayofweek, hourofday], 24*7)
-
Choosing the number of hash buckets is an art, not a science
-
The number of hash buckets controls sparsity and collisions
- Small hash_buckets → lots of collisions
- High hash_buckets → very sparse
Embedding Feature Crosses
- Creating an
embedding columnfrom a feature cross - The
weightsin the embedding column are learned from data - The model learns how to embed the feature cross in lower-dimensional space
Where to Do Feature Engineering
-
Three possible places to do feature engineering
- TensorFlow feature_column input_fn
- Dataflow
- Dataflow + TensorFlow (tf.transform)
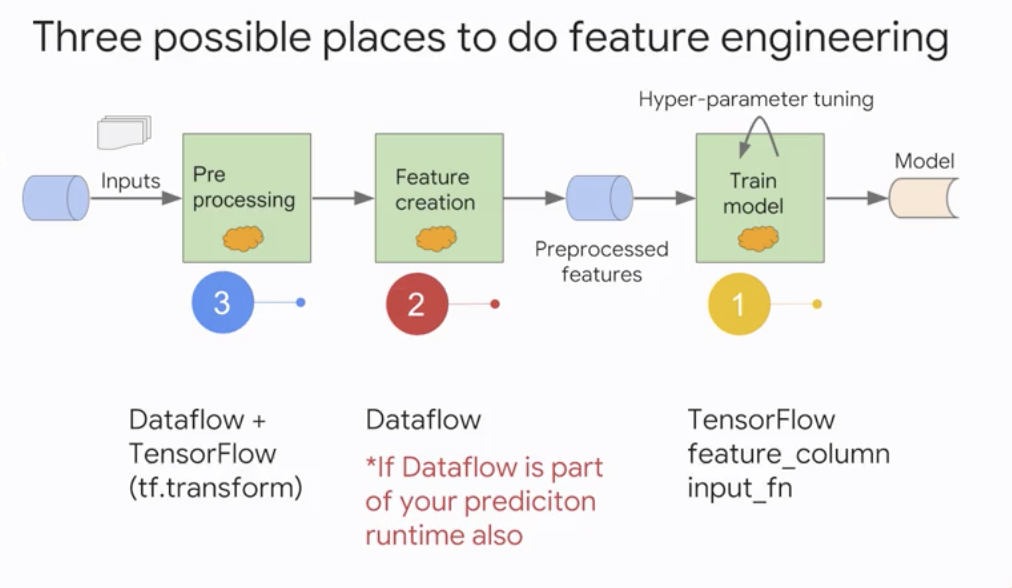
Three possible places to do feature engineering -
Some preprocessing can be done in
tf.feature_column -
Powerful preprocessing can be done in TensorFlow by creating a new feature column
latbuckets = np.linspace(38.0, 42.0, nbuckets).tolist()
lonbuckets = np.linspace(-76.0, -72.0, nbuckets).tolist()
b_lat = tf.bucketized_column(house_lat, latbuckets)
b_lon = tf.bucketized_column(house_lon, lonbuckets)
# feature cross and embed
loc = tf.crossed_column(house_lat, latbuckets)
eloc = tf.embedding_column(loc, nbuckets//4)
Feature Creation in TensorFlow
- Create new features from existing features in TensorFlow
def add_engineered(features):
lat1 = features['lat']
lat2 = features['metro_lat']
latdiff = lat1 - lat2
...
dist = tf.sqrt(latdiff*latdiff + londiff*londiff)
features['euclidean'] = dist
return features
def train_input_fn():
...
features = ...
return add_engineered(features), label
def serving_input_fn():
...
return ServingInputReceiver(
add_engineered(features),
json_features_ph)
TensorFlow Transform
- Pros and Cons of three ways to do feature engineering
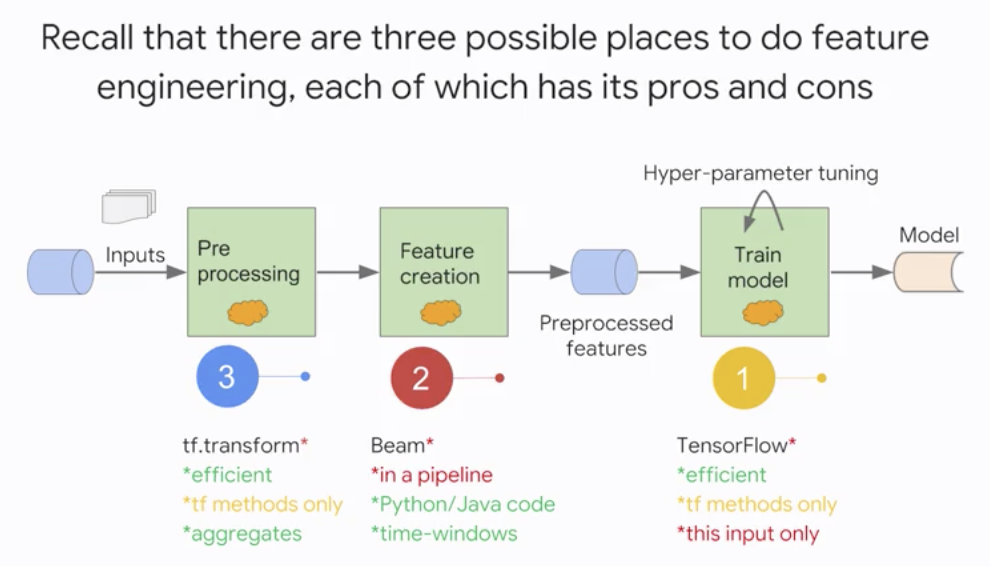
tf.transformis a hybrid of Beam and TensorFlowAnalyze- Beam- Find min/max value of numeric feature
- Find all the unique values of a categorical feature
Transform- TensorFlow- Scale inputs by the min & max
- One-hot encode inputs based on set of unique values
- tf.transform provides two PTransforms
AnalyzeAndTransformDataset- Executed in Beam to create the training datasetTransformDataset- Executed in Beam to create the evaluation dataset / The underlying transformations are executed in TensorFlow at prediction time
- tf.transform has two phases
Analysis phase(compute min/max/vocab etc. using Beam) Executed in Beam while creating training datasetTransform phase(scale/vocabulary etc. using TensorFlow) Executed in TensorFlow during prediction Executed in Beam to create training/evaluation datasets
Analysis phase
- First, set up the
schemaof the training dataset
raw_data_schema = {
colname : dataset_schema.ColumnSchema(tf.string, ...)
for colname in 'datofweek,key'.split(',')
}
raw_data_schema.update({
colname : dataset_schema.ColumnSchema(tf.float32, ...)
for colname in 'fare_amount,pickuplon,...,dropofflat'.split(',')
})
raw_data_metadata =
dataset_metadata.DatasetMetadata(dataset_schema.Schema(raw_data_schema))
- Next, run the
analyze-and-transformPTransform on training dataset to get back preprocessed training data and the transform function
raw_data = (p # 1.Read in data as usual for Beam
| beam.io.Read(beam.io.BigQuerySource(query=myquery, use_standard_sql=True))
| beam.Filter(is_valid)) # 2. Filter out data that you don't want to train with
# 3. Pass raw data + metadata template to AnalyzeAndTransformDataset
# 4. Get back transformed dataset and a reusable transform function
transformed_dataset, transform_fn = ((raw_data, raw_data_metadata)
| beam_impl.AnalyzeAndTransformDataset(preprocess)) - Write out the preprocessed training data into
TFRecords, the most efficient format for TensorFlow
transformed_data |
tf.recordio.WriteToTFRecord(
os.path.join(OUTPUT_DIR, 'train'),
coder=ExampleProtoCoder(
transformed_metadata.schema)
Transform phase
- The preprocessing function is restricted to TensorFlow function you can call from TensorFlow graph
def preprocess(inputs):
result = {} # Create features from the input tensors and put into "results" dict
result['fare_amount'] = inputs['fare_amount'] # Pass through
result['dayofweek'] = tft.string_to_int(inputs['dayofweek']) # vocabulary
...
retult['dropofflat'] = (tft.scale_to_0_1(inputs['dropofflat'])) # scaling
result['passengers'] = tf.cast(inputs['passengers'], tf.float32) # Other TF fns
return result
- Writing out the eval dataset is similar,except that we reuse the transform function computed from the training data