Coursera 강의 “Machine Learning with TensorFlow on Google Cloud Platform” 중 다섯 번째 코스인 Art and Science of Machine Learning의 강의노트입니다.
Review Embedding
- Creating an embedding column from a
feature cross. - The weights in the embedding column are
learned from data. - The model learns how to embed the feature cross in lower-dimensional space
- Embedding a feature cross in TensorFlow
import tf.feature_column as fc
day_hr = fc.crossed_column([dayofweek, hourofday], 24*7)
# Transfer Learning of embedding from similar ML models
day_hr_em = fc.embedding_column(day_hr, 2,
ckpt_to_load_from='london/*ckpt-1000*',
tensor_name_in_ckpt='dayhr_embed',
trainable=False
)- Transfer Learning of embeddings from similar ML models
- First layer: the feature cross
- Second layer: a mystery box labeled latent factor
- Third layer: the embedding
- Fourth layer: one side: image of traffic
- Second side: image of people watching TV
Recommendations
- Using a
second dimensiongives us more freedom in organizing movies by similarity - A
d-dimensionalembedding assumes that user interest in movies can be approximated by d aspects (d < N)
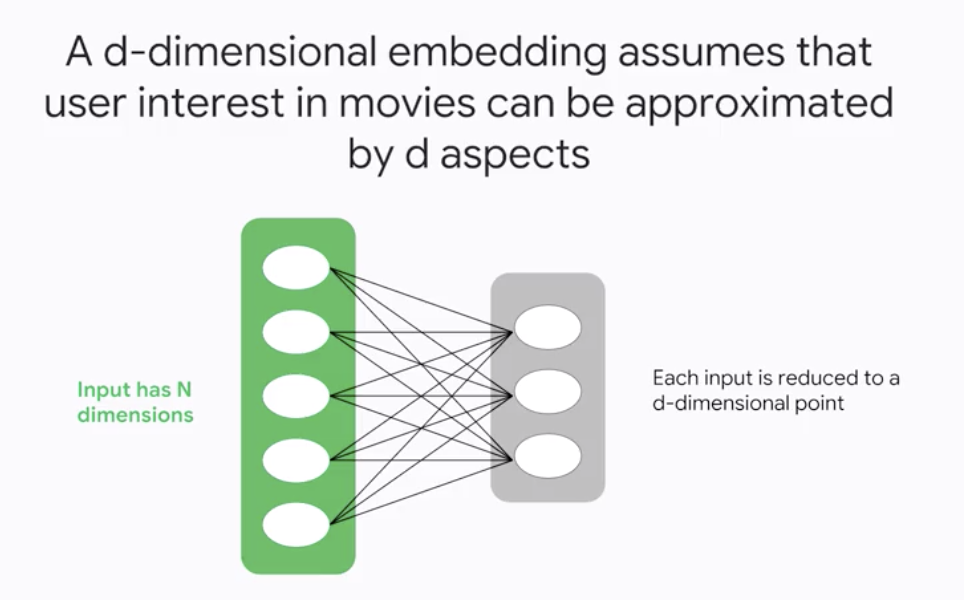
Data-driven Embeddings
- We could give the axes names, but it is not essential
- Its’ easier to train a model with d inputs than a model with N inputs
- Embeddings can be learned from data

Sparse Tensors
-
Denserepresentations are inefficient in space and compute -
So, use a
sparse representationto hold the example- Build a dictionary mapping each feature to an integer from 0, … # movies -1
- Efficiently represent the sparse vector as just the movies the user watched
-
Representing feature columns as sparse vectors (These are all different ways to create a categorical column)
- If you
know the keysbeforehand:
- If you
tf.feature_column.categorical_column_with_vocabulary_list('employeeId',
vocabulary_list = ['8345', '72345', '87654', '98723', '23451'])
- If your data is
already indexed: i.e., has integers in[0-N):
tf.feature_column.categorical_column_with_identity('employeeId',
num_bucket = 5)
- If you don’t have a vocabulary of all possible values:
tf.feature_column.categorical_column_with_hash_bucket('employeeId',
hash_bucket_size = 500)Train an Embedding
- Embedding are feature columns that function like layers
sparse_word = fc.categorical_column_with_vocabulary_list('word',
vocabulary_list=englishWords)
embedded_word = fc.embedding_column(sparse_word, 3)- The weights in the embedding layer are learned through
backpropjust as with other weights - Embeddings can be thought of as
latent features.
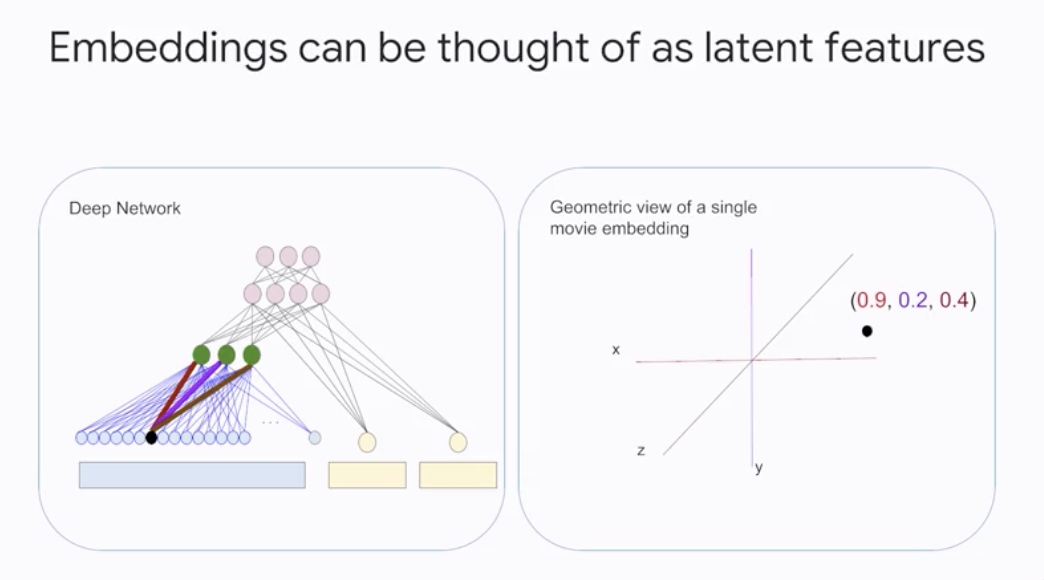
Similarity Property
- Embeddings provides
dimensionality reduction.
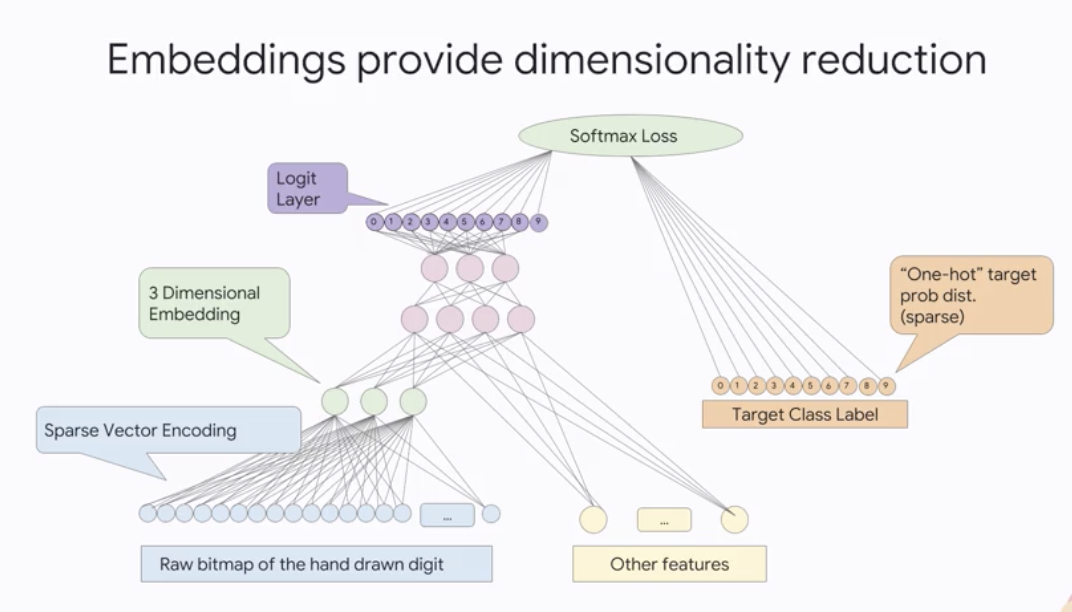
-
You can take advantage of this similarity property of embeddings
-
A good starting point for number of embedding dimensions
- Higher dimensions →
more accuracy - Higher dimensions →
overfitting,slow training - Empirical tradeoff
- Higher dimensions →
Custom Estimator
- Estimator provides a lot of benefits
- Canned Estimators are sometimes insufficient
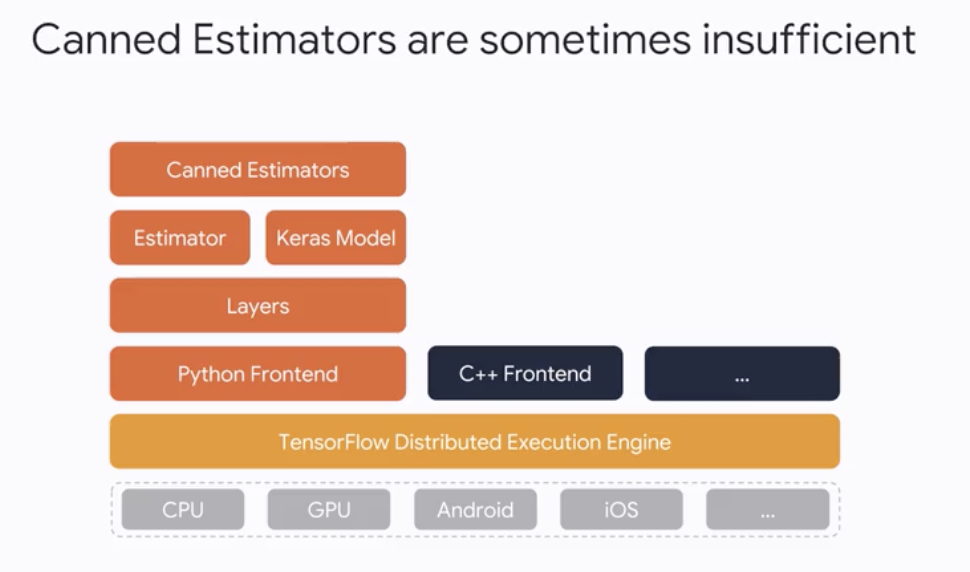
-
Suppose that you want to use a model structure from a research paper…
- Implement the model using low-level TensorFlow ops
def model_from_research_paper(timeseries):
x = tf.split(timeseries, N_INPUTS, i)
lstm_cell = rnn.BasicLSTMCell(LSTM_SIZE, forget_bias=1.0)
outputs, _ = rnn.static_rnn(lstm_cell, x, dtype=tf.float32)
outputs = output[-1]
weights = tf.Variable(tf.random_normal([LSTM_SIZE, N_OUTPUTS]))
bias = tf.Variable(tf.random_normal[N_OUTPUTS]))
predictions = tf.matmul(outputs, weights) + bias
return predictions
-
How do we wrap this custom model into Estimator framework?
-
Create
train_and_evaluate functionwith the base-class Estimator
def train_and_evaluate(output_dir, ...):
estimator = tf.estimators.Estimator(model_fn = myfunc,
model_dir = output_dir)
train_spec = get_train()
exporter = ...
eval_spec = get_valid()
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)-
myfunc (above) is a
EstimatorSpec.- The 6 things in a EstimatorSpec
Modeis pass-through- Any tensors you want to return
LossmetricTrainingopEvalops- Export outputs
def myfunc(features, targets, mode):
# Code up the model
predictions = model_from_research_paper(features[INCOL})
# Set up loss function, training/eval ops
... # (next code)
# Create export outputs
export_outputs = {"regression_export_outputs":
tf.estimator.export.RegressionOutput(value = predictions)}
# Return EstimatorSpec
return tf.estimator.EstimatorSpec(
mode = mode,
predictions = predictions_dict,
loss = loss,
train_op = train_op,
eval_metric_ops = eval_metric_ops,
export_outputs = export_outputs)
- The ops are set up in the appropriate mode
if mode == tf.estimator.ModeKeys.TRAIN or
mode == tf.estimator.ModeKeys.EVAL:
loss = tf.losses.mean_squared_error(targets, predictions)
train_op = tf.contrib.layers.optimize_loss(
loss=loss,
global_step=tf.contrib.framework.get_global_step(),
learning_rate=0.01,
optimizer="SGD")
eval_metric_ops = {
"rmse" : tf.metrics.root_mean_squared_error(targets, predictions)}
else:
loss = None
train_op = None
eval_metric_ops = NoneKeras Models
- Keras is high-level deep neural networks library that supports multiple backends
- Keras is easy to use for fast prototyping
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)- From a compiled Keras model, you can get an Estimator
from tensorflow import keras
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Get estimator from keras
estimator = keras.estimator.model_to_estimator(keras_model=model)- You will use this estimator the way you normally use an estimator
def train_and_evaluate(output_dir):
estimator = make_keras_estimator(output_dir)
train_spec = tflestimator.TrainSpec(train_fn, max_steps = 1000)
exporter = LatestExporter('exporter', serving_input_fn)
eval_spec = tf.estimator.EvalSpec(eval_fn,
steps = None,
exporters = exporter)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)- The connection between the input features and Keras is through a naming convention
model = keras.models.Sequential()
model.add(keras.layers.Dense(..., name'XYZ'))
def train_input_fn():
...
features = {
'XYZ_input': some_tensor,
}
return features, labels