이 포스트는 케라스 창시자에게 배우는 딥러닝 (Machine Learning with Python)의 내용 중 3.2장을 바탕으로 작성되었습니다.
케라스 소개

케라스는 거의 모든 종류의 딥러닝 모델을 간편하게 만들고 훈련시킬 수 있는 파이썬을 위한 딥러닝 프레임워크입니다.
케라스의 특징은 다음과 같습니다.
- 동일한 코드로 CPU와 GPU에서 실행 할 수 있습니다.
- 사용하기 쉬운 API를 가지고 있어 딥러닝 모델의 프로토타입을 빠르게 만들 수 있습니다.
- (컴퓨터 비전을 위한) CNN, (시퀀스 처리를 위한) RNN을 지원하며 이 둘을 자유롭게 조합하여 사용할 수 있습니다.
- 다중 입력이나 다중 출력 모델, 층의 공유, 모델 공유 등 어떤 네트워크 구조도 만들 수 있습니다. 이 말은 GAN(Generative Adversarial Network) 부터 뉴럴 튜링 머신까지 케라스는 기본적으로 어떤 딥러닝 모델에도 적합하다는 뜻입니다.
한편, 케라스는 딥러닝 모델을 위한 고수준의 구성 요소를 제공하는데, 텐서 조작이나 미분 같은 저수준의 연산은 다루지 않습니다. 대신에 케라스의 백엔드 엔진 에서 제공하는 최적화된 텐서 라이브러리를 사용합니다. 케라스는 모듈 구조로 구성되어 있어 하나의 텐서 라이브러리에 국한하여 구현되어 있지 않고, 여러 가지 백엔드 엔진과 매끄럽게 연동됩니다. 현재는 TensorFlow, Theano, CNTK 3개를 백엔드 엔진으로 사용할 수 있습니다.
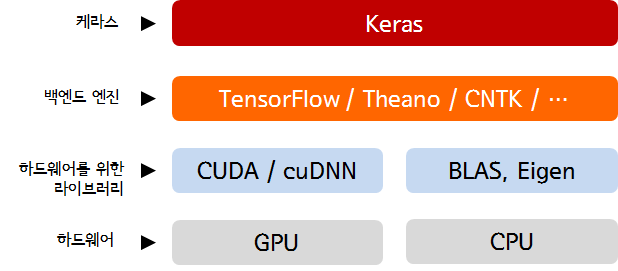
딥러닝 소프트웨어와 하드웨어 스택
TensorFlow, Theano, CNTK는 딥러닝을 위한 주요 플랫폼 중 하나입니다. 또한 케라스로 작성한 모든 코드는 아무런 변경 없이 이런 백엔드 중 하나를 선택해서 실행시킬 수 있습니다. 개발하는 중간에 하나의 백엔드가 특정 작업에 더 빠르다고 판단되면 언제든지 백엔드를 바꿀 수 있어 아주 유용합니다. 가정 널리 사용되고 확정성이 뛰어나는 텐서플로가 대부분의 딥러닝 작업에 기본으로 권장됩니다.
백엔드 엔진을 변경하는 방법(링크)
$HOME/.keras/keras.json파일로 들어갑니다.
참고로 Windows 환경에서는$HOME$을%USERPROFILE%로 대체하면 됩니다.keras.json은 아래와 같은 구조로 되어있는데,backend필드를 간단하게"theano","tensorflow", 나"cntk"로 변경해주면 됩니다.
기본 설정은 아래와 같이"tensorflow"로 되어있습니다.{ "image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow" }
- 또한
KERAS_BACKEND환경변수를 선언하면keras.json파일에서 선언한 백엔드를 오버라이드 할 수도 있습니다.KERAS_BACKEND=tensorflow python -c "from keras import backend" Using TensorFlow backend.
케라스를 이용해서 개발하기 (MNIST 데이터 이용)
케라스를 사용한 대부분의 작업 흐름은 다음과 같습니다.
- 입력 텐서와 타깃 텐서로 이루어진 훈련 데이터를 정의합니다.
- 입력과 타깃을 매핑하는 층으로 이루어진 네트워크(또는 모델)를 정의합니다.
- 손실 함수, 옵티마이저, 모니터링하기 위한 측정 지표를 선택하여 학습 과정을 설정합니다.
- 훈련 데이터에 대해 모델의
fit()메서드를 반복적으로 호출합니다.
한편, 모델을 정의하는 방법은 두 가지인데, Sequential 클래스(가장 자주 사용하는 구조인 층을 순서대로 쌓아 올린 네트워크입니다.) 또는 함수형 API (완전히 임의의 구조를 만들 수 있는 비순환 유향 그래프(DAG)를 만듭니다.)를 사용합니다.
지금부터 가장 기본적인 신경망 예제인 MNIST 데이터셋을 이용해 손글씨 데이터를 분류 예측하는 모델을 만들어 보겠습니다. 다행히 keras에는 MNIST 데이터셋이 numpy 배열 형태로 포함되어 있으며, 다음과 같이 불러올 수 있습니다.
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
이제 위에서 이야기했던 Sequential 클래스를 사용하여 정의한 모델을 살펴보겠습니다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(784,)))
model.add(layers.Dense(10, activation='softmax'))
같은 모델을 함수형 API를 사용하여 만들어 보겠습니다.
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32, activation='relu')(input_tensor)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)
함수형 API를 사용하면 모델이 처리할 데이터 텐서를 만들고 마치 함수처럼 이 텐서에 층을 적용합니다.
위의 두 모델은 조밀하게 연결된 (또는 완전 연결(fully connected)된) 신경망 층인 Dense 층 2개가 연속되어 있습니다. 마지막 층은 10개의 확률 점수가 들어 있는 배열을 반환하는 소프트맥스층입니다. 각 점수는 현재 숫자 이미지가 10개의 숫자 클래스 중 하나에 속할 확률입니다.
모델 구조가 정의된 후에는 Sequental 모델을 사용했는지 함수형 API를 사용했는지는 상관없으며 이후 단계는 동일합니다.
컴파일 단계에서는 학습 과정이 설정 됩니다. 여기에서 모델이 사용할 옵티마이저와 손실 함수, 훈련하는동안 모니터링하기 위해 필요한 측정 지표를 지정합니다.
model.complie(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
categorical_crossentropy는 손실 함수입니다. 가중치 텐서를 학습하기 위한 피드백 신호로 사용되며 훈련하는 동안 최소화됩니다. 그리고 미니 배치 확률적 경사 하강법을 통해 손실이 감소됩니다. 경사 하강법을 적용하는 구체적인 방식은 첫 번째 매개변수로 전달된 rmsprop 옵티마이저에 의해 결정됩니다.
마지막으로 입력 데이터의 넘파이 배열을 (그리고 이에 상응하는 타깃 데이터를) 모델의 fit() 메서드에 전달함으로써 학습 과정이 이루어집니다.
model.fit(train_images, train_labels, epochs=5, batch=128)
fit() 메서드를 호출하면 네터워크가 128개 샘플씩 미니 배치로 훈련 데이터를 다섯 번 반복합니다. 각 반복마다 네트워크가 배치에서 손실에 대한 가중치의 그래디언트를 계산하고, 그에 맞추어 가중치를 업데이트합니다.
마지막으로 전체 예제를 살펴보고 이번 포스트를 마무리 하도록 하겠습니다.
# 필요한 라이브러리 불러오기
from keras.datasets import mnist
from keras import models
from keras import layers
from keras.utils import to_categorical
# MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 이미지 데이터 준비하기 (모델에 맞는 크기로 바꾸고 0과 1사이로 스케일링)
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
# 레이블을 범주형으로 인코딩
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 모델 정의하기 (여기에서는 Sequential 클래스 사용)
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
model.add(layers.Dense(10, activation='softmax'))
# 모델 컴파일 하기
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# fit() 메서드로 모델 훈련 시키기
model.fit(train_images, train_labels, epochs=5, batch_size=128)
# 테스트 데이터로 정확도 측정하기
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('test_acc: ', test_acc)